PDF可查询化
 在纸质图书数字化的初期,为了尽快推出产品,很多数据提供商直接用扫描后的图像生成PDF文件,并没有做文字识别,这样的电子书仅能满足浏览的需要。
在纸质图书数字化的初期,为了尽快推出产品,很多数据提供商直接用扫描后的图像生成PDF文件,并没有做文字识别,这样的电子书仅能满足浏览的需要。
由于这些PDF文件仅包含图像数据,没有相应的文字,无法对其进行搜索。而利用搜索功能查找感兴趣的内容是现今大部分客户最常用的手段,所以对这些数据进行二次加工,使其能满足搜索需要是必然趋势。
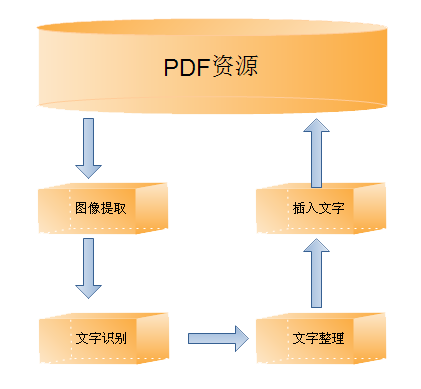
PDF可查询化方案正在在这样的背景下设计和开发的,它将PDF中的图像提取出来,交给成熟的OCR引擎进行文字识别,并对识别结果进行整理,最后通过版面还原达到文字与图像内容一致的效果(也就是双层PDF文件)。示意图如下:
技术优点
- 不需要折分已有的PDF文件,而是在现有的PDF文件基础上操作;
- OCR引擎可以根据需要灵活选择,中文可以选择汉王或者文通,外文可以选择FineReader;
- 自动处理过程中,不需要人工干预;
- 可以对已处理过的文件进行重新处理。一旦OCR引擎升级并且识别质量有所提升后,可以对文件进行重新处理。
- 处理速度极快,处理过程的90%以下时间由OCR引擎消耗。