PDF乱码修复
 所谓“PDF乱码 问题”,就是某些文本型的PDF文件,当用Adobe Reader(或其它任何能打开PDF文件的软件)打开浏览时,看到的内容没有任何异常。但是当从里面复制文字时,得到是一堆毫无意义的乱码。不论粘贴对象是Word还是UltraEdit或记事本,都是一样的结果。对于这样的PDF文件,不论用什么PDF浏览器,诸如Adobe Reader、FoxitReader还是什么Apabi或CajViewer。都无法从中复制到和原始内容匹配的文字。这样的PDF文件虽然不影响浏览,但是不能对其创建索引,所以也不能正常的检索。
所谓“PDF乱码 问题”,就是某些文本型的PDF文件,当用Adobe Reader(或其它任何能打开PDF文件的软件)打开浏览时,看到的内容没有任何异常。但是当从里面复制文字时,得到是一堆毫无意义的乱码。不论粘贴对象是Word还是UltraEdit或记事本,都是一样的结果。对于这样的PDF文件,不论用什么PDF浏览器,诸如Adobe Reader、FoxitReader还是什么Apabi或CajViewer。都无法从中复制到和原始内容匹配的文字。这样的PDF文件虽然不影响浏览,但是不能对其创建索引,所以也不能正常的检索。
产生乱码的原因
产生这种现象的主要原因是在生成PDF文件的过程中,由于PDF文件本身不利于反复编辑,所以大部分的PDF文件都是从其它格式的文件转换过来的。目前市场上提供这种转换功能的软件也很多,基本上可以分为两个类别:一种是使用“虚拟打印机”模式,另一种是通过分析文件格式一步一步的创建PDF文件。前一种比较常见。后一种在WPS中使用。
通常有这种问题的PDF文件都使用了内嵌字体。内嵌字体有很大的优越性,这种PDF文件无论在任何平台上显示,都能看到同样的效果。但是内嵌字体会使PDF文件的尺寸增大,同时如果没有很规范的使用内嵌字体,也会导致乱码现象的产生。
我们在分析问题的过程中,共发现大致三种类型的乱码:中文或符号数字英文乱码、全选时乱码但部分选择时正常,最后一种是选择时不正常,特别是在Adobe Reader中时,修复前后的效果如下图:


修复流程和策略
预处理
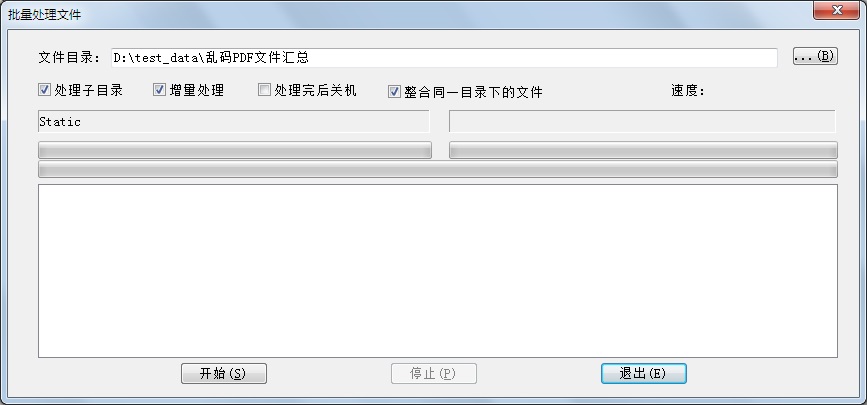
首先使用批量预处理模块对所有需要修复的PDF文件进行预处理。预处理做的工作是,对指定目录下的PDF做完整的分析,把在PDF每一页上出现所有字都收集到,合并相似度很高的字符(如此则可以减少校对的工作量)。这一步骤不需要人干预,指定好目录即可执行。由于预处理比较耗费时间,所以设计为双线程并处理。如下图:
校对
预处理完成之后,就可以对每个PDF文件进行校对了。此时以字体为单位列出每个字符的信息,可以查看每个字符的编码,如果上下一致则说明是正确,否则是错误的(即使在同一字体内部,也可能会出现部分字符有,而部分字符正确)。对于不正确的字体,可以先使用OCR做一扁识别,然后再人工校对。

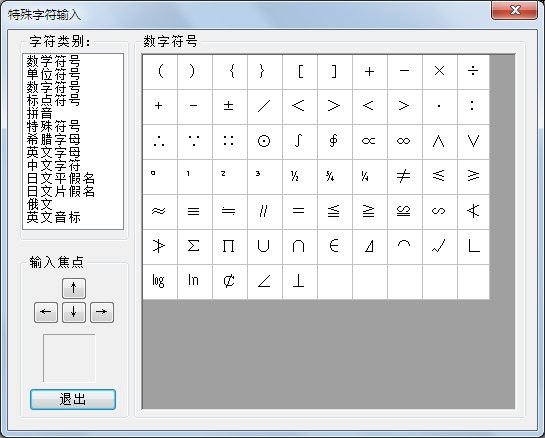
输入特殊字符
方便快捷地输入特殊字符(无法用键盘直接输入的字符)。部分常用的特殊字符会出现在右键菜单上,还可以弹出特殊字符窗口成批的输入。
纵校
在以字体为单位校对完成后,还可进行纵校。纵校列出相同编码的所有字符,查看是否有其它字符被错误编码。

整合校对
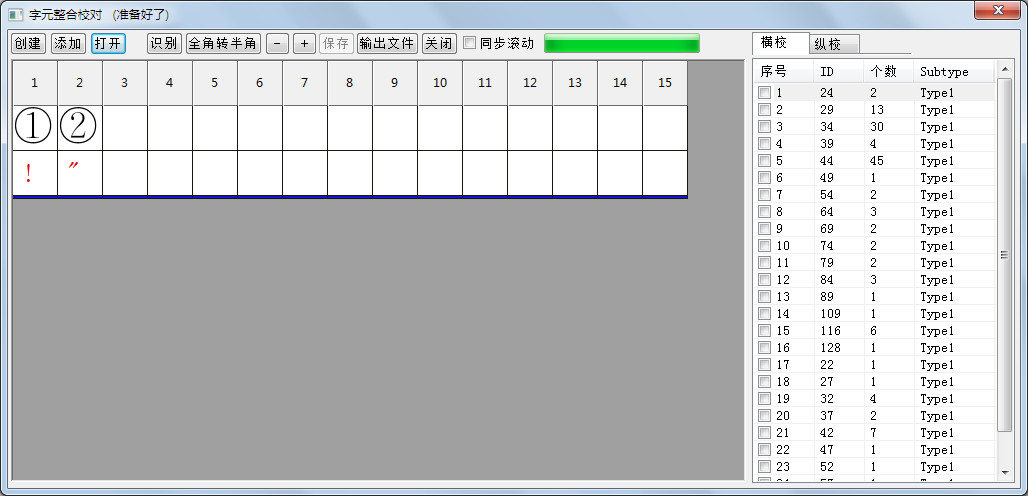
为了加快校对速度,还可以使用
整合校对。所谓整合校对是指对多个待校对文件再次执行合并,如此操作后,所有被合并文件中的相同字元只需要一次校对,此种策略对于相同来源的文件的效果非常好,因为相同来源的文件通常使用相同的字体和排版风格,校对效率以合并的文件数量而相应提高,整合越多,提高越多,目前最大支持合并32个文件。
输出文件
所有的字符都校对完成以后,即可输出新的PDF文件。在整合校对时,会为所有合并的文件都执行输出操作。